2024年を迎えた現在も、変わることなく「21世紀はデータ駆動社会(データドリブン)」「データマネジメントが重要」「DXを推進せよ」などとうたわれています。
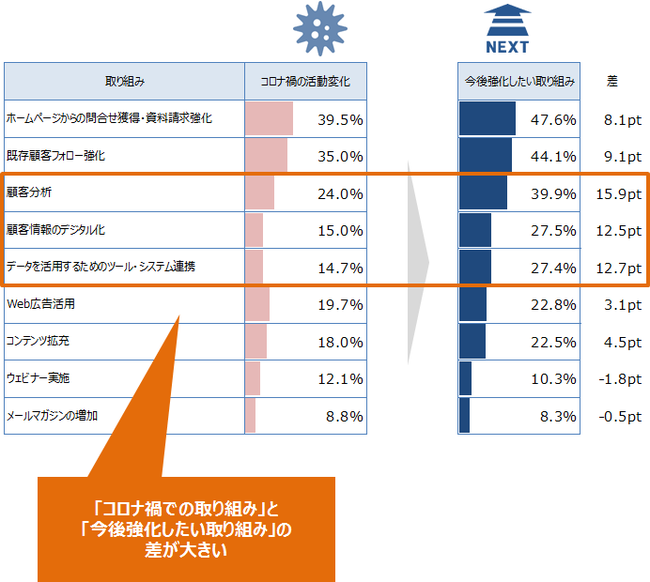
日本のBtoBマーケティング領域でも、コロナ禍をきっかけにデータ活用に向けての取り組みが進みつつあります。帝国データバンクが2021年に実施した「BtoBマーケティングのデータ活用に関するアンケート」では、3割近くの企業が「『顧客データのデジタル化』『データを活用するためのツール・システム連携』」を強化したい」と回答しています。
ほかの先進国に比べて遅れていた日本のデジタル化が、コロナがきっかけとはいえ加速するのは喜ばしいことです。
しかし、日々現場でデジタルマーケティングのお手伝いをしていると、現実はその理想よりもはるか手前の、基本の部分で躓いているケースがほとんどであると筆者は強く感じています。つまり、データマネジメントがほとんどできていない状況で、データドリブンなどは程遠いのが現実なのです。
特に「名寄せ」については、そういった理想と現実のギャップが散見される施策のひとつです。たとえば、データの半角、全角が統一されていない。あるいは各部門で個別に管理しているツールへのデータ入力の基準がバラバラで、必要なデータの定義がないなど、データに手をつけられない状態になっていることも珍しくありません。
本記事では、そんなデータマネジメントにおいて重要な「名寄せ」について解説します。
名寄せとは
名寄せとは、異なるデータソースから得られたデータを整理整頓して、同一データの重複や矛盾を排除して一貫性のある正確な状態に統合する取り組みです。
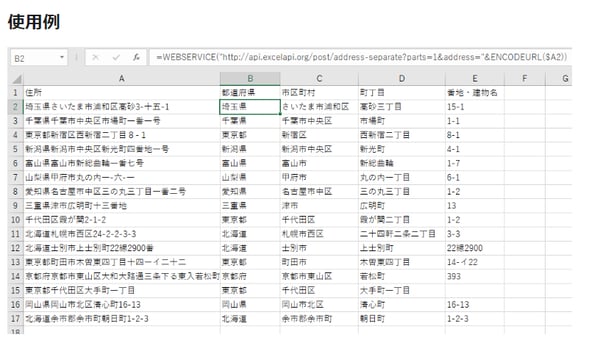
企業には、さまざまなチャネル経由で企業や個人の顧客データが登録されます。「無料ウェビナーに参加する」「Webから資料をダウンロードする」といった行動を通して、マーケティングの管理するMA(マーケティング・オートメーション)や、営業のSFA(営業支援システム)、CRM(顧客管理システム)に顧客データが登録されます。
この際、同一の顧客情報が、異なるツールにバラバラの形式で登録されることも珍しくありません。それぞれ入力フォーマットは違いますし、担当者や見込み客が正確な情報を入力しないこともあります。企業内のデータには誤入力、重複、表記ゆれなどが原因で同一人物が複数件扱いとなっていることは珍しくないでしょう。
名寄せとは、このような重複しているデータを整理整頓して、同一人物ないし同一企業のデータを1つに紐づけてまとめる作業です。
日本企業のもつ名前の特殊性
企業で収集したデータに表記ゆれが多いのは、日本の場合致し方ない側面もあります。
日本語はひらがな、カタカナ、漢字、英文字を駆使しているため、世界でも複雑な言語に分類されます。加えて、複雑な会社名の規則、前株、後株、カタカナ、ひらがな、複数の読み方がある漢字なども複雑性を増します。
ビジネスシーンでは、役職名や部署名では業務内容や役割が明確にわからない(例:参与、主査、エグゼクティブディレクター、〇〇代理、次〇〇第五部門、営業部マーケティング課、営業部販促支援部門etc)もあり、分類が極めて難しいのです。
読者の方にも、大人数の打ち合わせの後のお礼メールに「どの役職の方に、先に言及すればよいのか」と悩んだことも多いのではないでしょうか。
そのような複雑な言語体系ゆえに、たとえ表記の統一ルールを設けていても、顧客データマネジメントに課題を抱えている企業が多いと思います。
名寄せがBtoB企業にとってなぜ重要か?
では、BtoB企業にとって名寄せはなぜ重要なのでしょうか。代表的な恩恵を挙げると、以下のとおりです。
- 正確な顧客情報の管理ができる
- 必要なデータを探しやすくなる
- データによる意思決定・施策を加速できる
次項より、個別に解説します。
正確な顧客情報の管理ができる
名寄せにより、同一顧客に関するデータを一元化し、その顧客に関連する情報を得ることができます。これにより、顧客の過去の購入履歴、関心事項、コミュニケーション履歴などを把握し、顧客理解を深められるようになるのです。
顧客に関する正確な情報があれば、マーケティング施策やセールスアプローチをよりパーソナライズできます。これにより顧客への影響力を高め、コンバージョン率の向上に貢献します。
顧客からの問い合わせやサポートの際に、顧客の全体像を把握していれば、より迅速で質の高いサービスの提供が可能です。
必要なデータを探しやすくなる
名寄せを行うことで、異なるソースやシステムに分散していたデータが一元化され、必要な情報へのアクセスが容易になります。
名寄せではデータクレンジングという「表記ゆれや誤字脱字などの修正によるデータの一元化」を行いますが、これにより自社内でバラバラになっているデータが標準化され、データの整合性が向上し、データベース内での情報検索がより効率的になるのです。
(出典:FujiTsu)
データを整理して一貫性を持たせることで、データ管理が容易になり、データ運用にかかる人的コスト(例:手動でのデータ整理や重複チェックにかかる時間分の人件費)の削減にも繋がるでしょう。
データによる意思決定・施策を加速できる
正確に整理されたデータセットにより、データ分析も効率化され、迅速な意思決定が可能になります。一貫性のあるデータをもとにした分析を行えば、より信頼性の高いインサイトを得られ、データ駆動型の意思決定を実現できるでしょう。
たとえば、BtoB SaaS企業は、顧客からのフィードバックやプロダクトの利用データ(例:特定の機能の使用頻度や顧客による評価)の収集・分析に名寄せを役立てられます。名寄せした正確なデータをもとにすれば、顧客が最も価値を見出している機能や改善が必要な領域を特定します。
名寄せができてないと何の役にも立たないデジタルツールたち
オンラインでは、見込み客の行動ベースのデータまで収集できます。そこで、正しくデータマネジメントができていれば、MAやCRM、SFAなどのデジタルツールを活用した精度の高い分析が可能です。
ところが、このようなデジタルツールも「名寄せ」ができていないと何の役にも立たない可能性があります。以下より、その理由についてみていきましょう
MA(マーケティングオートメーション)の場合
マーケティング部門が活用するMAツールには資料ダウンロードなどの「オンライン経由の見込み客データ」と、展示会や他業種イベントで獲得した名刺情報などの「オフラインの見込み客データ」があります。
当然、何割かは自社の製品・サービスに関心を持つ貴重な見込み客データです。ここからリードナーチャリングやクオリフィケーションを行い、最終的には営業部門にホットリード(製品・サービス購入意欲の高い見込み客)として引き渡します。
マーケティング部門内でデータの名寄せができていないと、同一のリードを別の人物と認識してしまうリスクがあります。そうすると見込み度合いの推定がそもそも変わってきます。たとえば、セミナーに参加して、かつ資料をダウンロードしたリードであればスコアがその分加算されるはずが、別々に認識しているとそれぞれロースコアのままになるのです。
最近の傾向として、当社にもマーケティング部門がナーチャリングしたいという要望が増えています。しかし、データの定義や位付けができていないと、正確なリスト作りも難しく、リストに合わせたメールの内容作りが不可能で、メールの一括送信になってしまいます。
顧客視点に立てば「同じ情報が立て続けに送られて来る」「インサイドセールス部門から同じ内容で何度もアプローチがある」など、ツールによる自動化が自社の心象を損ねる要因になりかねないのです。
CRM/SFAの場合
CRMとは顧客情報管理システムですが、同じ企業内でもデータが整備されていないために「商品ごとにデータベースがある」「事業部門別に別のリストを抱えて営業している」などのケースはいまだ少なくありません。
場合によっては営業担当者個人で名刺管理をしている。あるいは、個人のエクセルファイルにて名刺情報を管理していることがあります。
SaaS企業の見込み客には、複数の製品・サービスを活用している企業も多いでしょうが、データベースが統合されていないと、「アップセル・クロスセルのために複数の営業担当者が同じ顧客に別々にアプローチする」といった事態も発生しかねません。
SFA(営業支援システム)にいたっては、「外部から購入したリスト」「営業担当者が名刺交換したリスト」「マーケティングから引き継いだリスト」が混在します。
こうなると、既存顧客は営業担当者からアプローチを受け、さらに違う事業部の営業担当者からアプローチを受けます。ご存知のとおり営業担当者のアプローチは1回では終わりません。3~4回、企業によっては延々とアプローチします。
SaaSのビジネスモデルは、データをきちんと活用することによって成り立つビジネスといっても過言ではありません。顧客データベースすら整備されていない企業が、果たして見込み客や既存顧客から信頼され続け、継続契約を行ってくれるでしょうか。
総じて、CRMやSFAにおける効果的な名寄せは、顧客情報の完全性と一貫性を保ち、顧客体験の向上、営業効率の最適化、データ駆動型の意思決定を実現するために不可欠なのです。
サードパーティーとのデータベース連携の場合
各種SaaSツールを利用していると、サードパーティー(外部企業、第3者の意)とデータベースを連携させ、マーケティング活用や営業活動で活用することがあります。
自社の顧客情報以外に外部企業のデータを紐づけて活用することは、より幅広い情報をもとに顧客属性を知り、その情報を元に事業活動に幅を持たせられますので、成果にプラスの面があります。たとえばDMやメール配信、場合によってはバナー広告の配信やアクセス解析ツールなどを行うことも可能です。
前述の帝国データバンクの調査結果でも、外部企業のデータベースを紐づけて活用しているチームの成果は、紐付けて活用していないチームより1.5倍高くなっています。
(出典:PR Times「コロナ禍でのBtoBマーケティング、3割の企業が「顧客データのデジタル化」を強化したい取り組みに挙げる」)
ただし、サードパーティーとの連携も名寄せができていないデータを活用すると、検討違いのアプローチを見込み客に行い続けることになり、ユーザー側から不評を買う可能性をはらんでいます。
特にデータ活用では、自社のデータベースが主軸となり、サードパーティーのデータはあくまで追加のデータです。
追加データを活用するには前提となる自社内のデータを整備した上で、外部から流入してくるデータにも整合性を持たせなければなりません。
サードパーティーのデータと自社データの間で一貫性がないと、データマッピング(異なるデータソース間で情報を関連付けること)が困難になります。これにより、データ連携の自動化や効率化が阻害されるのです。
名寄せの種類
一言で「名寄せをしよう」といっても、実際に求められる作業にはいくつかの種類分けがされます。たとえば、以下のように名寄せの種類は多岐にわたるのです。
- ①:1対1の名寄せ
- ②:多対1の名寄せ
- ③:多対多の名寄せ
- ④:新しい項目の名寄せ
- ⑤:異なる項目の名寄せ
次項より、個別にみていきましょう。
①:1対1の名寄せ
1対1の名寄せは、データ統合の基本形式のひとつであり、2つのデータセットを統合する際に用いられます。最もシンプルな名寄せで、両方のデータセットに共通の識別子(たとえば、顧客IDや製品コード)が存在し、それに基づいてデータが結合されます。
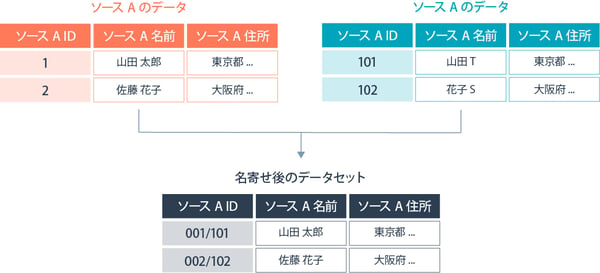
この方法では、一致しないレコードがある場合、それらは統合されずに残されるか、欠損値として扱われます。処理が比較的シンプルであり、データの結合において複雑なロジックが必要ありません。
BtoB SaaSにおける応用例としては、顧客情報の統合で活用できます。顧客の基本情報が含まれるデータセットと、その顧客の取引履歴が含まれるデータセットを統合する際に利用されます。
ほかにも、製品データベースと販売データを統合し、製品ごとの販売履歴や在庫情報を同期するといった使い方が可能です。
ただし、識別子となるデータの品質が低いと、正確な統合が困難になる可能性があります。たとえば、誤った顧客IDや不完全な製品コードがあると、正しい結合ができなくなります。
②:多対1の名寄せ
多対1の名寄せでは、1つのデータセット内の複数のレコードが、ほかのデータセット内の単一のレコードに関連付けられます。これは、特に階層的なデータ構造を持つ場合に有用です。
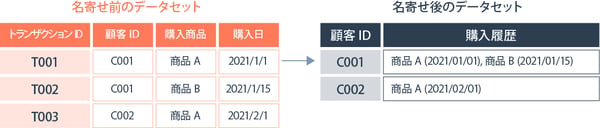
「多対1」の名寄せは、多くの個別の情報(例:トランザクションやイベント)を、それらの情報に関連する単一の項目(例:顧客や製品)にまとめるプロセスです。
たとえば、ある顧客が複数回にわたって製品を購入している場合を考えましょう。この顧客の各購入記録は、それぞれが個別のトランザクション(またはイベント)としてデータベースに記録されます。多対1の名寄せでは、これら複数の購入記録( = 多)を一つの顧客のプロファイル(= 1)にまとめます。
要するに多対1の名寄せは、たくさんの個々の活動や記録を、それらが関連する1つの大きなカテゴリ(たとえば、一人の顧客や一つの製品)にまとめ上げる方法です。これにより、顧客ごとの全体的な購入履歴や、製品ごとの総販売実績のような情報を簡単に把握することができます。
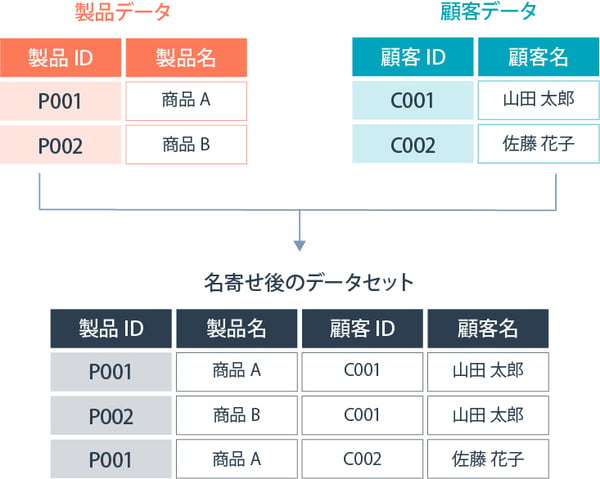
③:多対多の名寄せ
多対多の名寄せは、2つの異なるリストにおいて、同じ項目が複数回出現し、それらが相互に関連している状況で実施される名寄せです。
この場合、同じ識別子を共有する項目が両方のリストに複数存在するため、統合後のデータセットにはそれらのすべての組み合わせが現れる点が特徴です。
ここで、顧客IDと製品IDが共通の識別子となる場合、多対多の名寄せを実施すると、データセットAの顧客が行ったすべての行動と、データセットBの製品に関連するすべての行動が組み合わされたレコードが生成されます。つまり、ある顧客が関連するすべての製品に関して行った行動と、それら製品に関連するすべての行動が一つのデータセットに統合されることになります。
多対多の名寄せでは、統合後のデータセットは非常に大きくなることがあり、これがデータ処理や分析を複雑にしかねません。加えて、異なるデータセットからの情報を統合する際に、データの一貫性を保つことが難しくなるでしょう。
④:新しい項目の名寄せ
新しい項目の名寄せは、特定のデータセットに新しい行またはケースを追加する際に使用されます。具体例を挙げると、時間が経過するにつれて収集される新しいデータ(例:最新の販売記録や顧客フィードバック)を既存のデータセットに統合する場合などです。
BtoB SaaSでは、顧客からの継続的なフィードバックや市場のデータを収集し、既存のデータベースに定期的に追加する必要があります。特に、新しいデータを既存のデータセットに統合することで、時間の経過とともに変化するトレンドやパターンを分析でき、自社製品のアップデートや新サービスの開発に活かせるでしょう。
ただし、新しい情報を既存のデータベースやデータセットに統合する際、その新しい情報が既存のデータの形式や構造と異なる場合、データセット全体の一貫性や信頼性が低下するリスクがあります。
たとえば、既存のデータセットで日付が「YYYY-MM-DD」形式で記録されているのに対し、新しいデータでは「MM/DD/YYYY」形式で日付が記録されている場合、日付データの一貫性が失われてしまうでしょう。
新しいデータセットに、既存のデータセットにはない変数が含まれている。あるいはその逆の場合「欠損データをどのように扱うか」を定義しなければなりません。
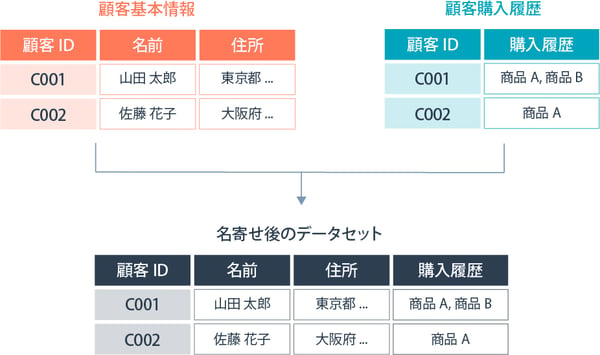
⑤:異なる項目の名寄せ
異なる項目の名寄せは、異なるデータセットから新しい変数(または列)を既存のデータセットに追加するプロセスです。このタイプの名寄せでは、異なるデータセットが同じエンティティ(例:同じ顧客や製品)に関する異なる情報を持っている場合に実施されます。
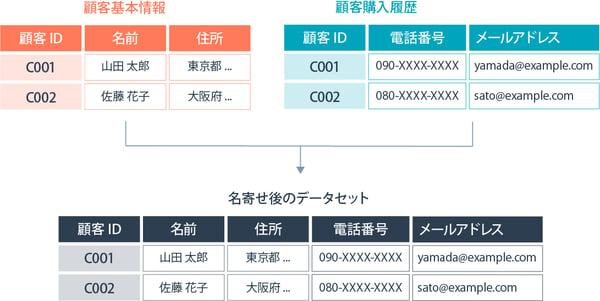
たとえば、1つのデータセットに顧客の基本情報があり、別のデータセットに顧客の購入履歴や嗜好情報がある場合、これらを統合することでより詳細な顧客プロファイルを作成できるでしょう。
異なる項目同士の名寄せを行う場合も、異なるデータソースからのデータを統合する際に、データ形式や内容の一貫性を保つ必要があります。
【まとめ】名寄せの種類ごとの違い
以上の各種名寄せの作業内容と、それぞれの異なる点をまとめると以下のように定義できます。
名寄せができていないと高確率で判別できる状態
では「自社が名寄せできているかどうか」の判断基準は、どこにおけばよいのでしょうか。各社の規模やビジネス要件にも依存するのですが、BtoB SaaS企業の場合は以下のポイントが「名寄せができていない状態」の判断基準として挙げられます。
- 問い合わせフォームが自由記入形式である
- 自動化メールが受信者の態度変容を無視している
- チャネル間でのデータ収集の一貫性がない
それぞれについて、詳しくみていきましょう。
問い合わせフォームが自由記入形式である
企業としては、自社サイトに訪問してくれた見込み客のデータをなるべく多く集めたいことでしょう。そのため、コンテンツにはかなりの労力をそそぐ一方で、リード獲得の最終段階である問い合わせフォームにまで気が回っていないケースも見受けられます。
問い合わせフォームが自由形式の場合、自社サイトの訪問者が情報を不完全に、あるいは不正確に入力する可能性があります。一般的に、Webからのリードの関心度合はそれほど高くない「少し興味を持った段階」です。自由に記入といってもそれほど書きこめないものなので、情報量も期待できません。
たとえば、同じ会社名でも略称やフルネームでバラバラに記載されることがあり、これが異なるデータ項目として扱われる原因になります。結果として、同一顧客のデータが複数存在する「重複」が発生し、名寄せの精度が低下してしまうのです。
自動化メールが受信者の態度変容を無視している
見込み客の関心度は、初期段階の「認知しているだけ」「なんとなく情報を知りたい」という軽い関心から、製品・サービスについて徐々に興味を持ちはじめます。
その後、MAを使ったメール配信によるリードナーチャリングなどの活動を通じて、活用事例や成果事例を知ってもらい、検討段階になってやっと費用対効果が気になり見積もりを依頼していただけるものです。

しかし、企業の配信メールの内容は多くの場合、態度変容を反映していないケースも珍しくありません。たとえば、貴社では以下のようなメール配信をしてしまっていないでしょうか。
- 相手のステージに関係なく事例ばかりを単調に送り続ける
- 見込み客対象のメールが既存顧客に送られる
自動化メールが受信者の現在の関心やニーズに合わせてカスタマイズされていない場合、それは顧客のデータが正確に更新または統合されていないことも意味します。
このような状態は、効果的な名寄せが行われていないことの兆候でしょう。
チャネル間でのデータ収集の一貫性がない
企業は、さまざまチャネルから見込み客のデータを収集します。大企業になると担当者もチャネルごとに違う場合もあります。
そのため、オフラインでの活動とオンラインでの活動における見込み客の収集フォーマットが異なり、データマネジメントがサイロ化しているケースも珍しくありません。
たとえば、展示会でのアンケートが会社名のフルネームを要求しているのに対し、オンラインフォームでは略称での入力が許されている場合、「役職不明」「社名が略されていて重複発生」など、正確な顧客プロファイルの構築が妨げる「汚いデータ」がどんどん溜まっていくでしょう。
これは、チャネル間で一貫したデータ収集方法が採用されておらず、名寄せが適切に行われていない状態を示しています。
名寄せが完了するまでの全体プロセスで必要な作業
ここからは、名寄せ完了までの全体プロセスにおいて必要な作業を、「①:名寄せ前→②:名寄せの実行中→③:名寄せ後」の3フェーズに細分化してみていきましょう。
①:名寄せ前
BtoB SaaSでは顧客データや製品情報、販売履歴など、自社ビジネスにとって重要なデータの品質と一貫性を保つことが重要です。
そのため、名寄せの前段階では、前提となるデータ整備のために以下のような作業が必要です。
- データプロファイリング
- データの標準化と変換
- データフィルタリング
- データの一意性の確保
それぞれ、個別に解説します。
データプロファイリング
データプロファイリングは、データソースの内容を分析し、データの品質、完全性、一意性、および分布を理解するための作業です。
データプロファイリングでは、各データソースの属性を分析して、統合する際に「どの情報が必要で、どのようにスケールするか」を把握するために行います。各データソースの属性を分析し、データ値の完全性と一意性を確認することで、統合後のデータの品質と一貫性を担保できます。
データの標準化と変換
標準化と変換は、データを共通のフォーマットや構造に整える作業です。この作業は、異なるデータソース間の形式や単位の違いを解消し、データ統合をスムーズに進めるために必要です。
印刷できない文字、空白値、余分なスペースなどの無効なデータを有効な値に置き換えることで、データセット全体の形式を統一できます。長いデータフィールドは適切に分割して、異なるソース間の整合性を確保し、統合のための特定の制約を設定しましょう。
データフィルタリング
データフィルタリングは、関連性のあるデータのみを選択し、不要または無関係なデータを除外する形で実施します。この作業は、統合の効率を高め、データセットの関連性と精度を向上させるために必要です。
まず、特定の期間内のデータや特定の条件を満たすデータのみを選択し、統合プロセスで不要な情報や重複を排除します。これにより、統合するデータセットの関連性と精度が向上するのです。
データの一意性の確保
「データの一意性」とは、データベースや情報システム内の各データがほかのデータと重複していない状態を意味します。平易に言い換えると「各情報が唯一無二であること」です。
データセット間で重複が存在する場合、これらを特定し、除去するためにあらかじめ定義しておいた「データ照合に関するルール」を適用する必要があります。これにより、すべてのソースでレコードの一意性が保たれるのです。
②:名寄せの実行中
名寄せの実行プロセスは、データの統合・集約のいずれかの形を採ります。この作業にはいくつか方法があり、次のものが挙げられます。
- 行の追加
- 列の追加
- 条件付き統合
以下より、詳細をみていきましょう。
行の追加
「行の追加」は、異なるデータセットからのレコード(情報のまとまり)を一カ所に結合する際に行います。名寄せで統合されるデータソースは同じ構造を持つ必要があり「データの種類」「データの形式の確認」「データの整合性やルール」が一致している必要があります。
なお、行の追加では複数のデータソースから得られた同一の対象(エンティティ)に関するデータを正確に組み合わせるために、「それらのデータが互いにどのように関連しているか」を特定する作業も求められます。
列の追加
「列の追加」とは、名寄せプロセスにおいて、異なるデータセットから新しい情報(列)を既存のデータセットに統合する作業を指します。たとえば、顧客データベースには顧客の基本情報が含まれているが、別のマーケティングデータベースには顧客の購入傾向や好みに関する情報がある場合などに必要な作業です。
列の追加は、既存のデータセットに新しい情報を付加し、そのデータの範囲と深さを増す重要なプロセスであると捉えましょう。
条件付き統合
「条件付き統合」とは、名寄せプロセスにおいて、特定の条件やルールに基づいてデータを選択し、異なるデータセット間で統合する作業を指します。この手法は特に、データセットが不完全で、一部の情報をほかのソースから補充する必要がある場合に使用されます。
たとえば、あるデータセットに顧客の基本情報があるが、別のデータセットにその顧客の購入履歴がある場合、購入履歴の情報を基本情報があるデータセットに追加可能です。
このプロセスを通じて、不完全なデータセットにほかのソースからの情報を補充し、より完全で詳細な情報を持つデータセットを作成できます。
③:名寄せ実行後
名寄せ作業が完了したら、最終的なデータセットを再度確認し、統合中に発生した可能性のあるエラーや不正確な値を特定する必要があります。とはいえ、膨大なデータセットを確認する作業は労力がかかりますので、自動化ツールの使用も検討しましょう。
たとえば、米Talendの提供するデータ管理ソリューションTalendなら、「自動化された品質チェック機能」「データの詳細な履歴を含めて追跡を行えるカタログ機能」などにより、データ監査の作業を大幅に効率化できます。
(出典:Talend)
もちろん、名寄せ後のデータ監査に利用するだけでなく、自社のデータガバナンス全体の強化にも繋がりますので、導入の意義は大いにあるでしょう。
名寄せの具体的なやり方と必要ステップ
前述した「名寄せの実行」で行う作業については、厳密には以下のようなステップに分けられます。
- ステップ1:営業活動で必要なデータの策定
- ステップ2:マーケティング活動で必要なデータの策定
- ステップ3:部門間での必要なデータの目線合わせ
- ステップ4:データの抽出
- ステップ5:データクレンジング
- ステップ6:分析のための属性情報の形式化
- ステップ7:データマッチング
- ステップ8:デジタルツールにサードパーティーのデータをインポート(マッピング)
次項より、具体的な方法についてみていきましょう。
ステップ1:営業活動で必要なデータの策定
まずは、直接顧客と関わる営業で必要なデータを定義する必要があります。営業活動で必要なデータは、以下のものが挙げられるでしょう。
<営業活動で必要なデータ例>
上記に加えて、自社の営業プロセスの体制によって必要となる情報が異なります。
たとえば、サードパーティーのデータやWebサイトでの行動履歴など以外にも、BANT情報などの直接確認してみないとわからない情報もあるでしょう。次のステップでもいえることですが、自社のビジネス要件に応じて柔軟に必要なデータを定義しましょう。
ステップ2:マーケティング活動で必要なデータの策定
次に、マーケティング戦略の成功に直結する情報を特定し、収集する必要があります。企業情報や担当者情報など、基本的には営業と同様の項目も多くなるでしょう。ただし、マーケティングはそれに加えて以下のような顧客の行動データを集めなければなりません。
- Webサイトの訪問履歴(例:閲覧ページ、滞在時間、クリックパターン)
- ソーシャルメディアの活動(例:「いいね」やシェア、フォロー)
- 資料ダウンロード履歴
- イベント参加履歴(ウェビナー、セミナー)
マーケティングでも営業と同様に、マーケティングプロセスを事前に構築し、各ステップにおいて必要な項目の定義付けをする必要があります。
いわゆるカスタマージャーニーを策定する重要性はそこにあり、BtoBにおける顧客の複雑な検討サイクルに関する情報をデータ上で定義し、活動内容や顧客レベルへ落とし込みましょう。
ステップ3:部門間での必要なデータの目線合わせ対象データ範囲の策定
一般にマーケティング部門がオフラインやオンライン上で見込み客を収集します。企業によってはテレアポ部隊にアウトソーシングし、マーケティング部門がリードマネジメントを実施。インサイドセールスがクオリフィケーションをし、より有望な見込み客を絞り込んで営業に引き渡します。
これはいわゆる「The Model」と呼ばれる分業体制です。部門間が連携して顧客対応にあたり、滞りなく顧客情報を共有するためには、事前に「他部門でどのようなデータが要るのか」についてすり合わせておく必要があります。
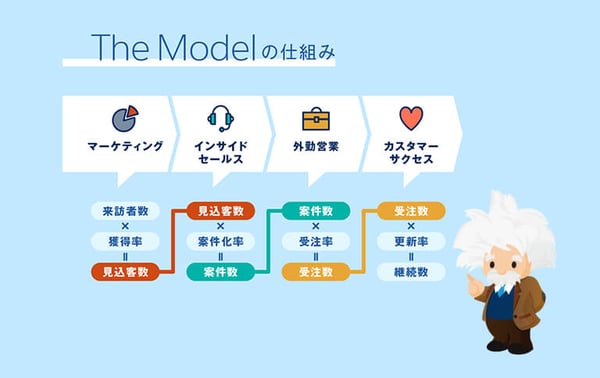
(出典:Salesforce「The Model(ザ・モデル)とは?用語と営業プロセスをSalesforceが解説」)
この際、データ入力のルール、データのアクセス権限、共有のタイミングなど、部門間でのデータ共有方法とポリシーを策定しておくとよりスムーズです。
特に「管理者、マネージャー、Manager、Manger(タイプミス)」など、役職や部署の名称で入力バリエーションが発生しやすい項目に対して、標準化された入力ルールを設けておくことで、後工程の作業をスムーズに進められます。
ステップ4:データの抽出
次に、各部門から決定された重要なデータ項目に基づき、データの抽出を行います。このステップでは、異なるソースからの関連データを特定し、必要な情報を集約する作業を実施する必要があります。
具体的には各部門に点在している「異なるデータソース(例:CRM、SFA、Web分析ツールなど)」から関連データを取り出し、整合性を確認する作業です。
抽出したデータは、重複や矛盾がないか検証し、必要に応じて修正しましょう。これにより、後続の名寄せプロセスで使用するための、クリーンで信頼性の高いデータセットのベースを作成できます。
ステップ5:データクレンジング
データクレンジングとは、データセットから不正確、不完全、重複する、または不適切な部分を修正または削除するプロセスを指します。
タイプミス、誤った日付や数値、間違った顧客情報など、不正確なデータを特定し、自社で決めた表記ルールにもとづいて揃えていきましょう。具体的なクレンジングの実施例としては、以下のようなものです。
ルールを整備していたとしても、名寄せをする前の段階では「重複しているデータ」「まったく使いものにならないデータ」も存在するでしょう。表記ルールを統一することで重複していたデータが判明しますので、このような不要なデータを削除可能です。
ステップ6:分析のための属性情報の形式化
次に、収集したデータが分析しやすい形式に整えるため、データの入力形式の定義を決める必要があります。
この段階では、顧客データ、取引データなどの属性情報を一貫した形式に標準化し、データの比較や統合が容易になるようにします。
特に、BtoB SaaSにおいて外部ソースからのデータ流入は頻繁に発生し、これらのデータはさまざまな形式や品質で提供されることが多いため、「流入段階から標準化されている」仕組み作りも効果的です。
たとえば問い合わせフォームなどで、役職名を自由記入ではなく、経営層、ゼネラルマネージャー層、ミドルマネジメント層などの選択肢を事前に用意しておくといった対応方法が挙げられます。
これにはMAやCRM、SFAなどのツールは、データの対象数を数えてレポートや対象となるリストを作成するため、対象者がカウントできる形式でないと機能しないという事情もあります。
問い合わせフォームを前述した自由記入形式にしていた場合、そのような場合入力データはほぼ集計不可能な状態になるため、避けるのが賢明です(人力集計は可能ですが...)。
ステップ7:データマッチング
データのマッチングは、抽出したデータセット間で同一のエンティティ(例:特定の顧客や製品)に関連する情報を統合するプロセスです。この段階では、異なるソースからのデータを統合し、重複や不一致を識別。最終的に一貫性のある単一のデータセットを作成します。
たとえば、2つの異なるデータリストがあり、それぞれに顧客情報が含まれているとします。データマッチングでは、これらのリストを並べて、同じ顧客に関する情報を見つけ出すのがマッチング作業です。
データマッチングも人力で行うには骨の折れる作業であるため、ここでもツールの活用が推奨されるでしょう。たとえば、株式会社アグレックが販売している「Precisely Trillium(日本版)」は項目値の類似度を細かなスコアリングで評価し「一致/不一致」を判定できますので、効率的なマッチング作業が可能です。
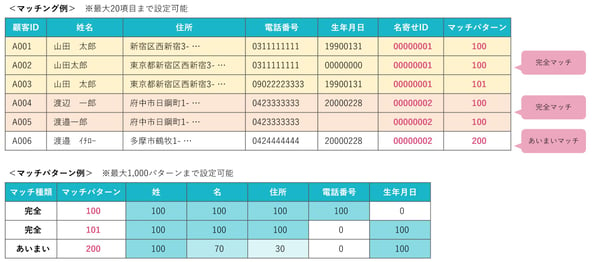
(出典:AGREX「名寄せとは?顧客情報整備に欠かせないデータクレンジングの仕組みを解説!」)
人間がデータを入力する際のタイプミスや、異なるデータ入力スタイルのため、完全に一致しないケースもあります。そのため、似ているけれど完全には一致しないレコードを特定するためには「一致判定」の基準を柔軟に調整しなければなりません。
ステップ8:デジタルツールにサードパーティーのデータをインポート(マッピング)
これらの準備が全て整った後は、デジタルツールにサードパーティ経由で得られる情報も統合することで名寄せが完了します。なぜなら、自社のみで収集したデータは、通常、自社の顧客や直接のビジネス活動に関連する情報に限られており、これでは市場全体の動向や潜在顧客に関する深い理解を得ることが難しくなるためです。
一方で、売買されているデータは一般化されたものが多く、業界情報は日本標準産業分類などに準じていることがほとんどです。
業界特化型のSaaSの場合、自社の業界データの詳細度とサードパーティーのデータの詳細度が異なることも珍しくありません。その場合、サードパーティーのデータをそのまま利用するのは難しいため、必要項目(と中身)を統合元のデータに合わせた形に変換する必要があります。
この作業をデータマッピングと呼び、異なるソースからのデータを統合し、一貫性を持たせることで、データ分析やビジネス意思決定に役立てることが可能です。
まとめ
名寄せは、BtoB SaaS企業においても、各部門に点在するデータを有効活用する上では、不可欠な取り組みです。
もちろん、手軽にExcelでも可能ですし、名寄せツールもかなり増えていますが、本記事ではあえてツールについては触れてません。
どのような手法で名寄せをするのであれ、まずは基本的な表記ルールを整え、各チャネルでデータの流入口部分のフォーマットを連携させることが最初のステップとなります。
21世紀のビジネスは、誇張抜きに「データが起点となるビジネス」です。データをいかに収集・分析し戦略に活かせるかが勝負の分かれ目ともいえます。
とはいえ、基本となるのは基本的な社内ルールを統一し、データマネジメント、データクレンジングの体制を整えるという泥臭い作業です。ツールを使った効率化を図る前に、名寄せの必要性と、各作業の意図について理解を深めた上で、社内の足並みが揃ったデータ運用の目的意識を持ちましょう。

著者情報 戸栗 頌平(とぐりしょうへい)
株式会社LEAPT(レプト)の代表。BtoB専業のマーケティング支援会社でのコンサルティング業務、自社マーケティング業務、営業業務などを経て、HubSpot日本法人の立ち上げを一人で行い、後に日本法人第1号社員マーケティング責任者として創業期を牽引。B2Bの中小規模企業のマーケティングに精通。趣味で国外のマーケティングイベント、スポーツイベント、ボランティアなどに参加している。
