顧客データの獲得に注力している企業は多いですが、適切にデータを活用できているでしょうか。例えば、顧客データに表記ゆれや重複、記入漏れなどがあれば、正確なデータ分析ができないどころか、顧客体験の低下や顧客離れなどの深刻な損失をもたらす恐れさえあるのです。
Gartner(ガートナー)社の調査によれば、低品質のデータは年間平均1500万ドルの損失をもたらし、約60%の企業はそもそも低品質のデータがもたらす財務影響を計算していないため、損失を受けていることにさえ気づいていません。
このようなリスクを防ぎ、適切にデータを活用するためには、データを整理整頓する「名寄せ」が必要です。しかし、いざ名寄せを行おうとしても、社内に詳しい人材がおらず、やり方が分からないとお困りの方もいるのではないでしょうか。
そこで本記事では、名寄せにおけるデータクレンジングや役立つエクセル関数を実例を用いながらご紹介します。
名寄せとは
名寄せとは、複数のデータベースに分散されている顧客情報を統合し、同一人物や同一企業を特定する手法です。具体的には名前やメールアドレス、住所、電話番号などの属性が一致する顧客/企業を「同一顧客」と判別します。
なぜ名寄せをすることが大切なのか
企業には多くのデータが集まりますが、誤入力や重複、表記ゆれなどが原因で同一人物が複数扱いになっている可能性は高いです。これでは同じ人物に、同じメールの繰り返し配信や同じ顧客に多くの営業担当がアプローチするなど、顧客の意思や状況を無視した施策を展開することになり、顧客体験の低下や顧客離れを招く恐れがあります。
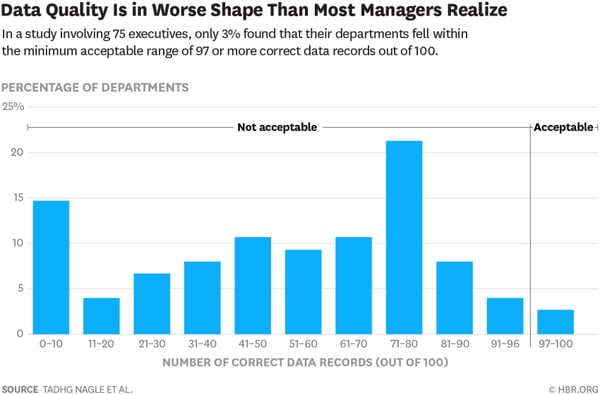
(出典:Only 3% of Companies’ Data Meets Basic Quality Standards|Harvard Business Review)
「自社に限って品質の低いデータを扱っているはずはない」と思う担当者の方もいるでしょう。コーク大学ビジネススクールが、75名のビジネスマネージャーを対象にした調査によれば、新たに作成されたデータレコードの47%に重大なエラーがあり、データ品質の基準を満たしていたのは全体のたった3%だと判明しました。
また、株式会社NTTデータ経営研究所の「企業におけるデータ活用の取り組み動向調査」によると、回答者の21%が「データの入力率・正確性が低い」ことをデータ活用における課題として挙げています。
これらの調査結果からも、企業内に蓄積されたデータは高確率でエラーが含まれていると考えるべきでしょう。だからこそ、名寄せで企業内にあるデータの統合と整理整頓をして、戦略に活かせるデータ分析の準備をしなければいけません。
名寄せとは?BtoB企業であれば知っておくべきデータマネージメントの重要性
よくある名寄せの状況ごとのエクセルとスプレッドシートでの対策方法
名寄せでよくある状況は下記のとおりです。
- データの入力ミス
- 記述揺れ
- 企業の連絡先の判別
ここからは、よくある名寄せの状況とその対処法をご紹介します。エクセルとスプレッドシートで実例を用いながら解説するため、ぜひご参考にしていただければと思います。
名寄せあるある1:データの入力ミスをエクセルで整理する
データの空欄を発見
セル上にデータが入力されていなければ、比較や演算処理を適切に行えません。まずは下記手順でデータが入力されていない箇所を発見し、空欄箇所があればデータを補足しましょう。
確認するデータの範囲を選択。
[ ホーム ] > [ 条件付き書式 ] > [ 新しいルール ] の順にクリック。
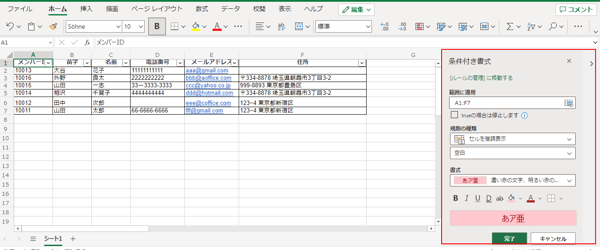
[ 規則の種類 ] には 「セルの強調表示」と「空白」、[ 書式 ] は一目で空白が分かるように「明るい赤」を設定し、[ 完了 ] をクリック。
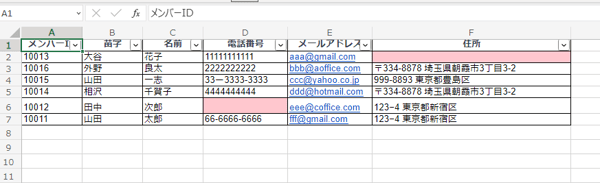
データが入力されていない箇所が明るい赤で表示されました。明るい赤で表示された箇所には、適切なデータを入力しましょう。
不要なスペースの削除
データに不要なスペースがまぎれている場合、検索やソート(並び替え)、フィルタリングなどができない恐れがあります。
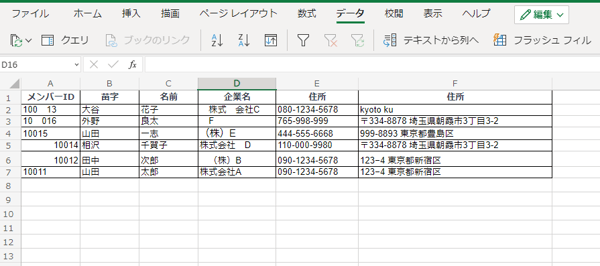
例えば上記画像は、メンバーIDを降順で並べかえたものですが、不要なスペースの存在により、適切に並べ替えられていないと分かります。スペースの削除法として、よく知られているのは「TRIM関数」。しかし、以下画像を見るとわかる通り、TRIM関数では単語間の空白は削除できません。
単語間の空白も削除したい場合は、指定した文字を新しい文字に置き換える「SUBSTITUTE関数」が有効です。
使い方は、「=SUBSTITUTE(文字列,”検索文字列”,”置換文字列”)」。半角スペースを削除する場合は検索文字列に半角(=” “)、全角スペースを削除する場合は全角(=” ”)、半角と全角スペースを削除するなら「=SUBSTITUTE(SUBSTITUTE(A2," ","")," ","")」のように入力しましょう。
今回は半角と全角スペースの両方を削除してみます。
文字列の前後だけではなく、単語間のスペースもきれいに削除できました。
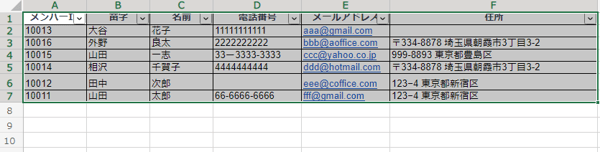
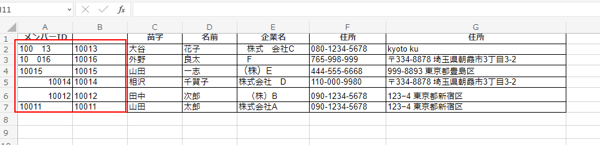
重複情報をどうするか
複数のデータベースより顧客情報を統合すると、顧客情報が重複することが多々あるため、重複データを削除しましょう。なお、誤って重要データを削除するリスクもあるため、必ずデータのコピーを作成してから作業に取りかかってください。
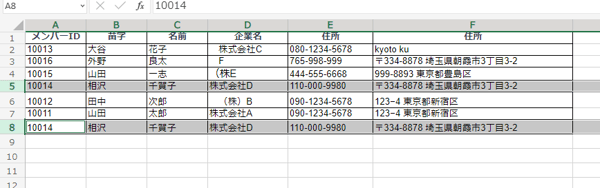
上記画像では、「メンバーID10014」の顧客情報が重複しています。このままだと、この顧客に同じメールを複数回送信したり、売上金額の正確な計算ができなくなったりします。
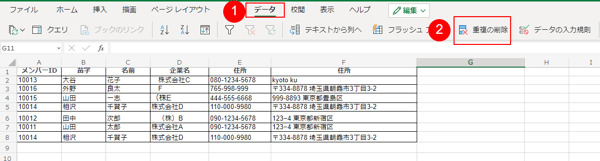
重複データを削除する範囲を選択し、[ データ ] > [ 重複の削除 ] の順に選択。
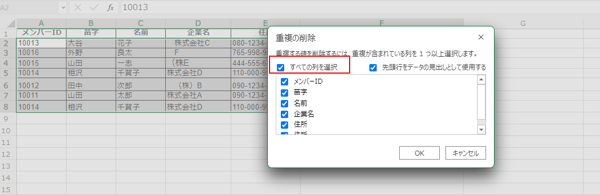
[ すべての列を選択 ] にチェックをいれて [ OK ] をクリック。これで重複データの削除は完了です。繰り返しになりますが、重複データの削除をする前は、必ずコピーを作成しておきましょう。
名寄せあるある2:「記述揺れ」をエクセルで整理する
数字は全角か半角か
名寄せでよくある課題の一つが記述揺れです。データセットの中に、全角と半角表記で混ざっていることはよくあるでしょう。下記画像をご覧ください。

「住所」欄における数字が全角と半角表記で記載されています。全角と半角表記は「ASC関数」で解決。

D列の2行目に「=ASC(テキスト)」を入力。

すると数値が半角に変換されました。

この関数をコピペすると、全ての住所の数字と英字を半角表記に統一できます。
住所の番地表記対策
住所の管理方法は、大きく「1セル内にすべての住所を記述する方法」と「都道府県・市区町村・番地/町名に分けて管理する方法」があります。
マーケティングや営業施策などでデータを活用することを踏まえれば、都道府県や市区町村などで分けるのがよいでしょう。そうすることで、東京都に住むユーザーにはリスティング広告に多くの費用を投下し、関西に住むユーザーには費用を抑えるなどの施策へとつなげられます。
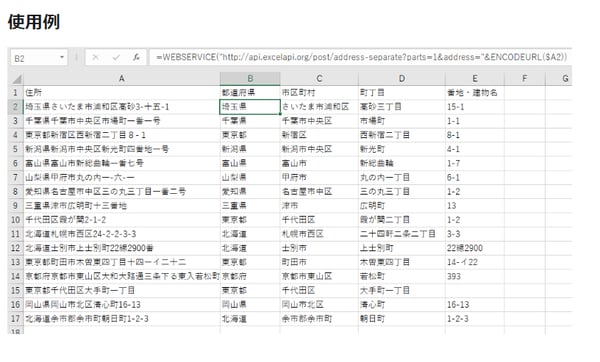
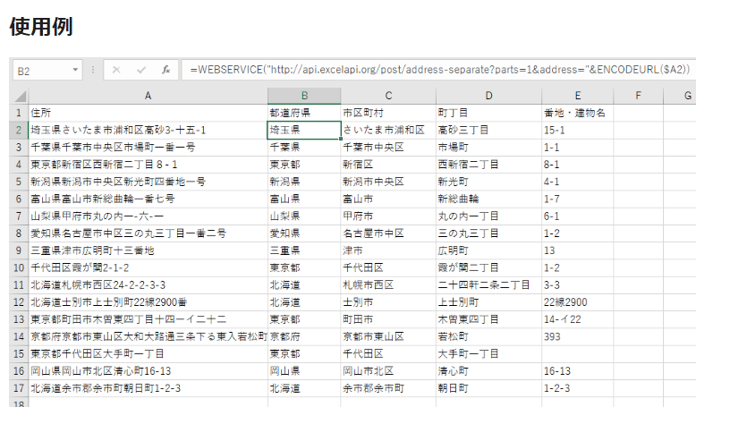
(出典:住所の分割|ExcelAPI)
住所の分割は、指定文字の分割や文字列の抽出などで行えますが、ExcelAPIで公開されている住所の分割APIのコピー&ペーストが簡単です。こちらのページより、関数をコピーして、エクセルに張り付けましょう。なおスプレッドシートで使える関数も用意されています。
株式会社か(株)かなどすべて統一
BtoB企業が名寄せをする場合、「株式会社」と「(株)」表記がデータセットに混ざっていることはよくあります。この問題は「REGEXREPLACE」で解決できます。REGEXREPLACE関数は、「REGEXREPLACE(テキスト,”正規表現”,”置換”)」で使用し、正規表現にマッチしたものが置換に設定した単語に変換されます。今回は「(株)」を「株式会社」表現に変更しましょう。
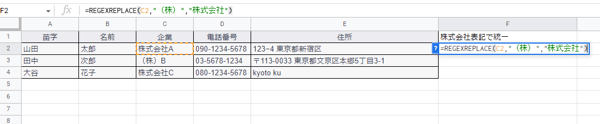
C列2行目を選択し、「=REGEXREPLACE(C2,"(株)","株式会社")」を入力。
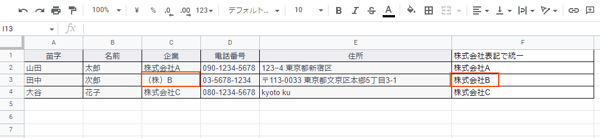
[ Ctrl ] + [ Shift ] + [ ↓ ] で関数を下までコピーすると、「(株)」が「株式会社」に統一されました。
社名の統一(例:日本電気、NEC)
複数のリソースからデータを統一した場合、「NEC」と「日本電気」のように企業名が正式名称と愛称で記載されているかもしれません。社名を統一するには、「検索と置換」で対応するのがよいでしょう。
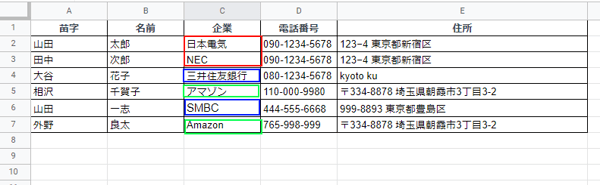
まずは社名の定義をします。本記事においては、下記のように定義します。
- 日本電気 ⇒ NEC
- アマゾン ⇒ Amazon
- 三井住友銀行 ⇒ SMBC
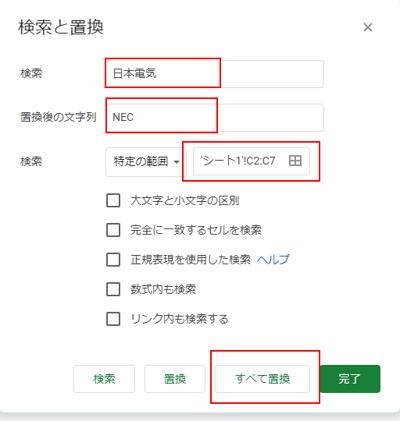
[ 編集 ] > [ 検索と置換 ] の順に選択し、置換たい企業名と置換後の文字列、検索範囲を指定し、[ すべて置換 ] をクリックして完了です。
電話番号と(-)の有無
データセットに電話番号が含まれている場合、「111-1111-1111」のようにハイフンが含まれているものと「22222222222」のようにハイフンが含まれていないものが混同している可能性が高いです。この対処法としては、ハイフンの追加もしくは削除が挙げられます。まずはハイフンを追加する方法を見ていきましょう。
電話番号にハイフンを追加する際は、下記関数を用います。
- LEFT関数:文字列の先頭(左)から指定された数の文字を返す
- MID関数:文字列の指定された位置から、指定された数の文字を返す
- RIGHT関数:文字列の末尾から指定された文字数を返す
電話番号は「○○-○○○○-○○○○」のように、左から2文字目にハイフン、右から4文字目にハイフンが来るため、下記のような関数を入力しましょう。
- =LEFT(E2,2)&"-"&MID(E2,3,4)&"-"&RIGHT(E2,4)
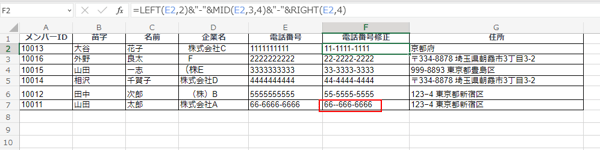
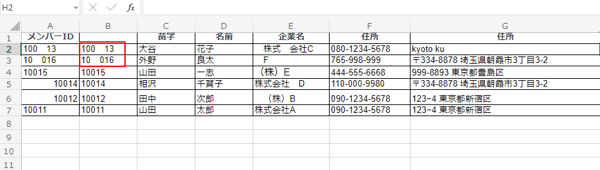
この関数を簡単に解説すると、左から2文字、真ん中から4文字、右から4文字を抜き出し、&で「-」をつけるというもの。しかし、この方法では上記画像の赤枠部分のようにハイフンが2つくっつく可能性があり、地域によって市外局番が3桁や4桁になるため、適切に対応するのが難しいです。
そこでおすすめしたいのが、先にご紹介した「SUBSTITUTE関数」でハイフンを取り除く方法。ハイフンは半角と全角で記載されている可能性があるため、下記の関数を入力します。
- =SUBSTITUTE(SUBSTITUTE(E2,"-",""),"ー","")
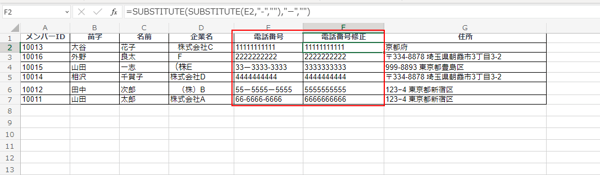
ご覧のとおり、半角と全角のハイフンが取り除かれ、電話番号のフォーマットが統一されました。
名寄せあるある3:企業の連絡先の判別をエクセルで解決する
フリーメルアドと企業メルアドの判別
企業を対象にしたメールマーケティングやキャンペーンを展開する場合、データセットより企業のメールアドレスを抽出する必要があります。フリーメールアドレスと企業メールアドレスを判別するには、下記関数を使用するのがおすすめ。
- =IF(ISNUMBER(SEARCH("@gmail", A1)), "Gmail", IF(ISNUMBER(SEARCH("@yahoo", A1)), "Yahoo", IF(ISNUMBER(SEARCH("@hotmail", A1)), "Hotmail", "Company")))
この関数を使えば、A1セルにあるメールアドレスが@gmail, @yahoo, @hotmailのいずれかである場合、それぞれ"Gmail","Yahoo","Hotmail"と表示し、それ以外のアドレスは"Company"と表示されます。
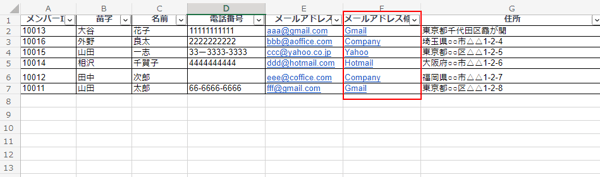
この関数を用いて、フリーメールアドレスと企業メールアドレス(Other)を分けてみました。上記画像では、データ数が少ないため企業のメールアドレスをすぐに確認できますが、データが多くなると確認は困難になります。
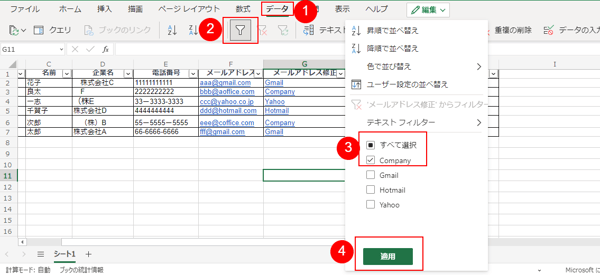
そこで [ データ ] > [ フィルター ] の順に選択して、メールアドレスをまとめた列にフィルターを作成し、「Company」だけ抽出します。
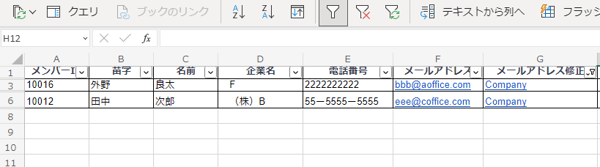
結果、上記画像の通り企業のメールアドレスを登録した顧客だけの表示に成功。ただし、この方法では「msn」や「softbank」、「docomo」などの関数で指定していないメールアドレスも「Company」と表示されてしまうため、フリーメールアドレスを漏れなく登録する、もしくはフィルターで抽出後に目視で確認と対応をする必要があります。
メールアドレスから企業名を抽出
BtoB企業の名寄せにおいては、企業名の整理は欠かせません。データセットに企業名が掲載されていない場合は、メールアドレスから会社名を抽出するとよいでしょう。基本的に、企業メールアドレスは「氏名@企業名.com」のように、@の後に企業名が来る傾向にあります。つまり、下記関数を用いて@以降を抽出すれば、メルアドから企業名を取得できるわけです。
- =RIGHT(F3,LEN(F3)-FIND("@",F3))
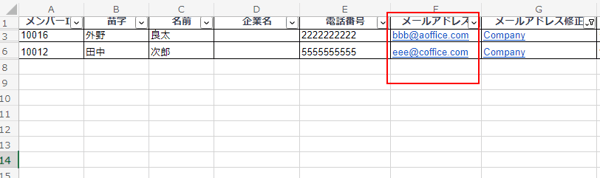
メールアドレスから「aoffice」と「coffice」という企業名を抽出します。
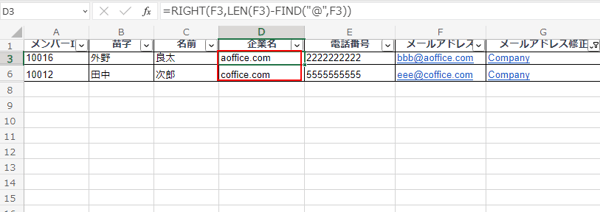
D3に「=RIGHT(F3,LEN(F3)-FIND("@",F3))」を入力し、下までコピーすると「aofiice.com」と「coffice.com」のみ抽出できました。「@」と「.com」を削除したい場合は、「=MID(F3,FIND("@",F3)+1,FIND(".",F3)-FIND("@",F3)-1)」を用います。
まとめ
現代のマーケティング活動において、データの活用は欠かせません。しかし、品質の低いデータを活用すれば、苦労して集めた顧客データを十分に活用できないどころか、競争力の低下や顧客の不信感を招いてしまいます。
データ分析によってインサイトを発見し、顧客に最適な価値を届けるためにも、名寄せでデータの整理整頓をしましょう。本記事でご紹介したように、エクセルやスプレッドシートでも十分に名寄せはできるため、定期的に名寄せを行っていただければと思います。

著者情報 戸栗 頌平(とぐりしょうへい)
株式会社LEAPT(レプト)の代表。BtoB専業のマーケティング支援会社でのコンサルティング業務、自社マーケティング業務、営業業務などを経て、HubSpot日本法人の立ち上げを一人で行い、後に日本法人第1号社員マーケティング責任者として創業期を牽引。B2Bの中小規模企業のマーケティングに精通。趣味で国外のマーケティングイベント、スポーツイベント、ボランティアなどに参加している。
